It Can Select, but It Cannot Create
AI recognizes what's funny but can't produce what's funny. We measured that with 2.5 million captions and 250 million human ratings.
이틀 전에 Lies of P를 썼다. AI는 왜 웃기지 않은가. 예측 오차를 최소화하도록 훈련된 시스템은, 예측을 깨뜨려야 성립하는 것을 만들 수 없다는 주장이었다.
쓰고 나서 불편했다. 논증은 깔끔했는데, 그게 진짜인지 모르겠었다. 가설이면 측정해야 한다. 그래서 측정했다.
핵심 질문
AI가 유머를 이해 못 하는 건지, 아니면 이해는 하지만 만들지 못하는 건지. 이 둘은 다른 능력이다. 시험 문제의 정답을 고르는 것과 정답을 처음부터 쓰는 것이 다른 것처럼.
이해한다면 → 재밌는 걸 골라낼 수 있어야 한다. 만들 수 있다면 → 재밌는 걸 생성할 수 있어야 한다.
이 격차를 proposal-selection gap이라고 불렀다.
데이터: 뉴요커 캡션 콘테스트
뉴요커 캡션 콘테스트 데이터셋을 썼다.1 362개 만화, 220만 개 캡션, 2억 5천만 개 인간 평점. 각 캡션에 수백 명이 1-3점으로 평가한 데이터다.
이 데이터의 장점: 인간의 판단이 이미 끝나 있다. AI한테 "이게 웃기냐"고 물을 필요 없이, 인간 평점이라는 ground truth가 있다.
실험 1: 선택 — "골라봐"
각 만화에서 인간 캡션 20개를 뽑았다. 최상위부터 최하위까지 골고루. AI한테 "가장 재밌는 3개를 골라"라고 했다.
결과:
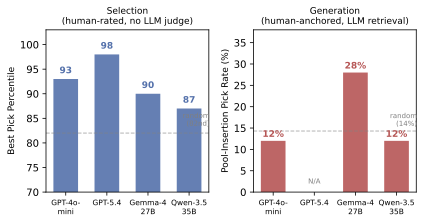
- GPT-5.4: 98번째 백분위
- GPT-4o-mini: 93번째 백분위
- Gemma-4 27B: 90번째 백분위
- Qwen-3.5 35B: 87번째 백분위
- 랜덤 (best-of-3): 82번째 백분위
모든 모델이 랜덤을 유의미하게 넘었다. AI는 재밌는 걸 안다.
실험 2: 생성 — "만들어봐"
같은 만화에 대해 AI한테 캡션을 5개 만들게 했다. 그중 최고를 골라서, 아까 그 20개 인간 캡션 풀에 21번째로 익명 삽입. 같은 GPT-5.4한테 "21개 중 top-3 골라"라고 했다.
AI 캡션이 top-3에 뽑힌 비율:
| 조건 | 뽑힌 비율 | 랜덤 기대값 | 유의미? |
|---|---|---|---|
| GPT-4o-mini (기본) | 12% | 14% | 아니오 (p=0.83) |
| GPT-4o-mini (힌트) | 24% | 14% | 경계 (p=0.09) |
| Gemma-4 27B | 28% | 14% | 예 (p=0.02) |
| Qwen-3.5 35B | 12% | 14% | 아니오 (p=0.83) |
대부분의 조건에서 AI 캡션은 랜덤과 구분되지 않았다.
선택에서는 98번째 백분위. 생성에서는 랜덤 수준. 같은 모델이다.
왜 이렇게 되나
재밌는 캡션은 예측을 깨는 캡션이다. 왕좌 위에 칼이 매달린 만화에서 "Your overhead is going to kill you"가 재밌는 이유 — "overhead"가 "경상비"와 "머리 위"를 동시에 뜻하니까. 확률이 낮은 출력이다.
AI의 학습 목표는 "가장 확률 높은 다음 토큰". 재미의 조건은 "확률이 낮은 토큰". 구조적 충돌이다.
그러면 선택은 왜 되나? 후보가 이미 있으니까. "A가 B보다 나은가?"는 패턴 매칭이다. 비교는 분포 안의 작업이다. 하지만 "아무것도 없는 상태에서 재밌는 걸 만들어라"는 분포 밖으로 나가야 한다.
인간 vs AI: 캡션 비교
| 만화 | 인간 최고 캡션 | AI 최고 캡션 |
|---|---|---|
| 왕좌 위 칼 | "Your overhead is going to kill you." | "Budget cuts have really taken a toll on royal safety." |
| 기린 거실 | "Sorry I'm late. I hit every traffic light." | "The signal is much better without the acacia tree." |
| 고래 섬 | "Who's endangered now?" | "Just cleaning up my dental hygiene." |
| 기차 레스토랑 | "If you see something, say something." | "Dining on the go didn't mean literally!" |
인간 캡션: 이중 의미, 프레임 전환, 아이러니 역전. AI 캡션: 문법적으로 완벽하지만 예측 가능하다.
발견: LLM 판사는 이 격차를 못 본다
실험 중에 예상 못 한 걸 찾았다.
GPT-4o-mini가 자기가 만든 캡션을 평가하면, 95% 확률로 자기 것이 더 낫다고 한다. GPT-5.4가 대신 판단하면 42%로 떨어진다. 53%p 자기선호 편향.
더 심각한 건: GPT-5.4의 쌍별 비교로 평가하면, AI 캡션과 인간 최고 캡션이 거의 같은 점수를 받는다 (r=0.50, p<0.001). LLM 판사는 "잘 쓴 것"과 "재밌는 것"을 구분하지 못한다.
현재 LLM-as-Judge로 창의성을 측정하고 있다면, 당신이 측정하고 있는 건 창의성이 아니라 언어적 품질일 수 있다.
정보를 더 주면 나아지나
"선택이 쉬운 건 답이 이미 있으니까 당연하지 않냐?"
이 반론을 위해: AI한테 선택과 동일한 정보(만화 설명과 20개 후보 캡션)를 보여주고, "이것들보다 더 재밌는 캡션을 만들어라"고 했다.
결과: 24%. 기본 생성(12%)보다 좀 낫지만 통계적으로 유의하지 않았다 (p=0.55).
같은 정보. 같은 모델. 선택은 93번째 백분위, 생성은 24%.
생성 → 선택: N을 늘리면?
"많이 만들어서 그중 최고를 고르면 되지 않나?"
해봤다. N=1, 5, 10, 20, 50으로 캡션을 생성하고 best-of-N으로 선택.
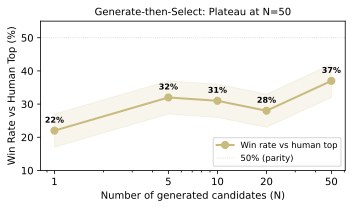
N=50에서 37%까지 올라갔지만 50% 패리티에는 못 미쳤고, N=20 이후로 plateau. 생성 분포 자체가 바뀌지 않으면, 검색(더 많이 만들어서 고르기)으로는 한계가 있다.
정리
AI는 재밌는 걸 안다. 98번째 백분위로. 하지만 재밌는 걸 만들지는 못한다. 랜덤과 구분되지 않는 수준으로.
이 격차가 유머에만 해당하는지, 창의성 전반의 구조인지는 아직 모른다.
다음
이 연구의 약점은 안다. 생성 평가가 완전히 인간 기반이 아니라 GPT-5.4를 매개로 한 human-anchored metric이라는 것. 뉴요커 캡션이라는 하나의 도메인이라는 것.
다음에 해야 할 세 가지:
-
인간 직접 평가. 사람한테도 21개 풀에서 top-3를 고르게 해서, GPT-5.4의 pick rate와 비교. 이게 맞으면 측정 반론이 거의 사라진다.
-
유머 너머. 과학적 가설 생성, 코드 리팩토링, 시각 디자인 — proposal-selection gap이 나타나는 다른 도메인 찾기. 유머가 특수한 건지, 창의성 전반의 패턴인지.
-
격차를 좁히는 방법. 인간이 제안하고 AI가 선택하는 시스템, 또는 AI가 대량 생성하고 인간이 고르는 시스템. generate-then-select가 N=50에서 37%로 plateau하는 건, 생성 분포 자체를 바꾸지 않으면 검색으로는 한계가 있다는 뜻이다.
Lies of P에서는 이렇게 끝냈다. "이미 존재하는 것들의 통계적 평균은 새로운 소수가 아니다."
이번 실험에서 확인한 건, AI가 소수를 알아볼 수는 있다는 것이다. 98번째 백분위로. 다만 아직 발견하지는 못한다.
Footnotes
-
Zhang, Y. et al. (2024). Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning. NeurIPS. ↩
Two days ago I wrote Lies of P. Why AI isn't funny. A system trained to minimize prediction error cannot produce something that depends on breaking predictions. Not jazz, not humor, not a prime number no one has seen before.
After writing it, I thought: this is not an essay, it's a hypothesis. It should be measurable.
Hypothesis
The idea was simple. Separate whether AI truly "doesn't understand" humor from whether it understands humor but "can't produce" it.
If it understands, it should be able to pick out a funny caption. If it can produce, it should be able to generate a funny caption. These are not the same ability -- just as choosing the right answer on a multiple-choice test is different from writing the right answer from scratch.
I called this the proposal-selection gap. The gap between selection and proposal.
Data
The New Yorker Caption Contest dataset.1 2.2 million captions submitted for 362 cartoons, with 250 million human ratings. Each caption was rated on a 1-3 scale by hundreds of people. No larger-scale humor evaluation dataset exists.
The advantage of this data is that human judgment is already done. There's no need to ask AI "is this funny?" People have already answered that.
Selection: 93rd Percentile
For each cartoon, I constructed a pool of 20 captions -- the top-rated caption, the lowest-rated, and 18 in between. I asked GPT-5.4 to "pick the 3 funniest."
The human ratings of GPT-5.4's picks landed at the 98th percentile. GPT-4o-mini hit the 93rd. Open-source Gemma-4 27B reached the 90th, and Qwen-3.5 35B the 87th. Random selection still yields the 82nd percentile -- since it's best-of-3. But every model significantly exceeded random.
So far, good news. AI recognizes what's funny.
Generation: Random-Level
I then asked AI to generate captions for the same cartoons. It produced 5, selected its best, and I anonymously inserted it as the 21st caption in the original pool of 20. The same GPT-5.4 was asked to "pick the 3 funniest out of 21."
Rate at which AI-generated captions were picked for the top 3:
| Condition | Pick Rate | p-value |
|---|---|---|
| GPT-4o-mini (baseline generation) | 12% | 0.83 |
| GPT-4o-mini (reference-guided generation) | 24% | 0.09 |
| Gemma-4 27B | 28% | 0.02 |
| Qwen-3.5 35B | 12% | 0.83 |
| Random | 14% | — |
In most conditions, AI captions were indistinguishable from random. Mixed in among 20 human captions, AI's output was on par with the average human submission.
98th percentile at selection. Random at generation.
Why This Happens
This is the empirical confirmation of what I argued in Lies of P. A funny caption is one that breaks predictions. "Your overhead is going to kill you" is funny in a cartoon of a throne with a sword hanging above it because "overhead" simultaneously means "operating costs" and "above one's head." That's a low-probability output. It collides head-on with AI's training objective -- output the highest-probability next token.
Why does selection work? Because the candidates already exist. "Is this caption better than that one?" can be answered by pattern matching. But "generate a funny caption from nothing" requires stepping outside the learned distribution.
The Limits of LLM-as-Judge
During the experiments, I found something unexpected.
When GPT-4o-mini judged its own captions, it rated them as superior 95% of the time. When GPT-5.4 judged instead, that dropped to 42%. A 53-percentage-point self-preference bias.
More interesting still: when evaluated via GPT-5.4's pairwise judgments, AI-generated captions and top human captions received nearly identical scores (validated correlation: r=0.50, p<0.001). In other words, the LLM judge fails to detect the gap.
Why? The LLM judge cannot distinguish "well-written" from "funny." AI captions are grammatically flawless, contextually appropriate, structurally clean -- they're just not funny. To the LLM judge, both look like "good captions."
This is a warning for the entire AI evaluation ecosystem. If you're measuring creativity with LLM-as-Judge, what you may actually be measuring is linguistic quality, not creativity.
Does More Information Help?
"Of course selection is easier -- the answers are already given."
To address this objection, I ran an additional experiment. I showed AI the same information available during selection -- the cartoon description and all 20 candidate captions -- then asked it to generate a new caption funnier than any of those (the G-hint condition). The result was 24%. Slightly above baseline generation (12%) but not statistically significant (p=0.55), and nowhere near the 93rd percentile achieved by selection with the same information.
Same information. Same model. Selection hits the 93rd percentile; generation hits 24%.
What I Learned from This Research
Measurement makes ideas more honest.
When I wrote Lies of P, I was confident. AI cannot be funny. A prediction machine breaking predictions is a contradiction. It was a clean argument, and I was satisfied with it.
Once I started measuring, that cleanness broke apart. AI hit the 98th percentile in selection -- so "it doesn't understand" was wrong. In LLM pairwise comparisons, generation and selection scored the same -- so "generation is clearly worse" was also wrong. Only when measured against human ratings did the gap emerge. And even that gap wasn't "AI can't do it at all" but rather "in most conditions, it's statistically indistinguishable from random."
In an essay you can write "AI isn't funny" in a single sentence. In a paper you have to write "GPT-4o-mini's pool-insertion pick rate is 12% [6%, 24%], not significantly different from random 14% (binomial p=0.83)."
Both sentences say the same thing, but the second one is more honest.
Looking Ahead
I'm aware of this paper's biggest weaknesses. The generation-side evaluation isn't purely human-based -- it uses a human-anchored metric mediated by GPT-5.4's retrieval. And it's limited to one domain: New Yorker captions.
Three things need to happen next.
First, direct human evaluation. Have people pick the top 3 from the 21-caption pool and compare their pick rates with GPT-5.4's. If the results align, nearly all remaining measurement objections disappear.
Second, beyond humor. Scientific hypothesis generation, structural code refactoring, visual design -- finding other domains where the proposal-selection gap appears. Whether humor is a special case or a pattern across creativity in general.
Third, closing the gap. Currently AI selects well but generates poorly. If so, a system where humans propose and AI selects -- or where AI generates in bulk and humans curate -- could outperform either alone. The observation that generate-then-select plateaus at 37% around N=50 implies that without changing the generation distribution itself, search alone has limits.
In Lies of P, I ended with this: "The statistical average of things that already exist is not a new prime number."
What this research shows is that AI can recognize a prime -- at the 98th percentile. But it still cannot discover one.
Whatever you call that gap -- the proposal-selection gap, the lie of prediction -- it remains an open problem.
Footnotes
-
Zhang, Y. et al. (2024). Humor in AI: Massive Scale Crowd-Sourced Preferences and Benchmarks for Cartoon Captioning. NeurIPS. ↩