Dissecting HOPE: Do Self-Modifying Memories Actually Self-Modify?
A systematic dissection of Google's Nested Learning (HOPE) architecture. Only one of three mechanisms is working — and not the way theory suggests.
초록
HOPE(Higher-Order Parametric Experience)는 Titans 메모리 아키텍처를 다중 시간 스케일 문맥 메모리(CMS), 자기수정 메모리 파라미터, 서프라이즈 게이팅이라는 세 가지 메커니즘으로 확장한다. 원 논문에서 종합 성능이 강력하지만, 각 메커니즘의 개별 기여도는 불분명하다. 본 연구에서는 컴포넌트 제거 실험, 내부 동역학 분석, 스케일링 실험으로 HOPE를 해부한다.
분석 결과 뚜렷한 비대칭성이 드러난다: (1) 자기수정이 HOPE 성능 우위의 유일한 동력이며, 그 중요도는 소규모에서 대규모 모델로 갈수록 4.5배 증가한다. (2) 다중 시간 스케일 CMS는 어떤 규모에서도 이득이 없으며, fast와 slow 레벨이 중복된 표현을 학습한다 (코사인 유사도 ≈ 0.77). (3) 서프라이즈 게이팅은 사실상 작동하지 않는데, 토큰별 손실이 합리적인 임계값을 훨씬 초과하여 (평균 = 66.7, 최솟값 = 9.3) >99.9%의 토큰에서 게이트가 열린다.
1. 서론
학습 가능한 메모리 시스템을 갖춘 신경망 아키텍처가 표준 트랜스포머의 고정 키-값 캐시에 대한 대안으로 새롭게 주목받고 있다. Titans는 경사 기반 업데이트를 통해 연상 패턴을 저장하고 검색하는 메모리 모듈을 도입하여, 준이차(subquadratic) 복잡도로 경쟁적 성능을 달성했다. HOPE는 메모리 활용을 개선하기 위해 세 가지 메커니즘으로 Titans를 확장한다:
- 문맥 메모리 시스템(CMS): 보완적 학습 시스템 이론에서 영감을 받아, fast, mid, slow 메모리 레벨이 서로 다른 빈도로 업데이트되는 다중 시간 스케일 계층.
- 자기수정 메모리: 추론 시점에 메모리의 key, value, query, 학습률 투영을 생성하는 메타학습 파라미터로, 모델이 자신의 업데이트 규칙을 적응시킬 수 있게 한다.
- 서프라이즈 게이팅: 토큰별 예측 손실에 기반하여 메모리 업데이트를 게이팅하는 메커니즘으로, "놀라운" 입력에 연산을 집중시킨다.
HOPE는 Titans 및 트랜스포머 대비 개선을 보고하지만, 원 논문의 평가는 종합 지표만을 제시한다. 이는 핵심 질문을 남긴다: 어떤 메커니즘이 실제로 성능에 기여하며, 이론적 동기 부여대로 작동하는가?
본 연구의 기여는 다음과 같다:
- 두 가지 규모에서의 완전한 컴포넌트 제거 실험을 통해 자기수정만이 HOPE의 성능 우위를 설명함을 보임.
- CMS의 fast/slow 레벨이 중복된 표현을 학습하며 측정 가능한 이득을 제공하지 않는다는 증거.
- 서프라이즈 게이팅이 학습 중 관측되는 손실 크기에서 사실상 비선택적임을 보이는 분석.
- 자기수정 동역학이 지속적 적응이 아닌 초기화 이동으로 나타남을 특성화.
- 자기수정의 중요도가 모델 크기에 따라 초선형적으로 증가함을 밝히는 스케일링 분석.
2. 배경
Titans. Titans 아키텍처는 어텐션에 신경 장기 메모리 모듈을 추가한다. 입력 시퀀스가 주어지면, 메모리 M은 연상 기억 목적함수에 대한 경사 하강법으로 업데이트된다: M ← M − η∇ₘℒ(M; k, v). 서프라이즈 지표 Sₜ = ‖ℒₜ‖는 각 토큰이 메모리 업데이트를 유발할지를 결정한다.
HOPE. HOPE는 세 축으로 Titans를 확장한다. CMS를 도입하여 다중 시간 스케일로 메모리를 유지한다: fast 레벨은 p_fast 토큰마다, slow 레벨은 p_slow 토큰마다 업데이트되며, 출력은 학습된 게이팅으로 결합된다. 다음으로 자기수정을 추가한다: key, value, query, 학습률에 고정 투영 행렬 대신 메타학습 네트워크 m_k, m_v, m_q, m_η, m_α, m_memory를 사용하여 teaching signal에 조건부로 투영을 생성한다. 생성된 파라미터는 추론 중 메타 파라미터에서 분기할 수 있는 "빠른 상태(fast state)"를 구성한다. 마지막으로 서프라이즈 임계값을 메모리 업데이트 선택성을 제어하는 하이퍼파라미터로 조정한다.
3. 실험 설정
모델 구성. 두 가지 규모를 평가한다:
- 소규모: dim=256, 6 레이어, ~19M 파라미터
- 대규모: dim=512, 8 레이어, ~73M 파라미터
모든 모델은 512 토큰 컨텍스트 길이를 사용하며, AdamW (lr=3e-4, 배치 크기=8)로 2,000 스텝 학습한다. CMS는 p_fast=8, p_slow=32의 업데이트 주기를 사용한다.
제거 실험 변형. 각 규모에서 다음 구성을 학습한다:
- Full HOPE: 세 메커니즘 모두 활성 (CMS + 자기수정 + 서프라이즈)
- No CMS: 다중 시간 스케일 메모리 없이 자기수정과 서프라이즈만 사용
- No Self-Mod: 자기수정 파라미터 없이 CMS와 서프라이즈만 사용
- No Surprise: 서프라이즈 임계값=0으로 CMS와 자기수정만 사용
- Transformer: 표준 트랜스포머 기준선
- Titans: 원본 Titans 아키텍처
대규모 설정에서는 HOPE의 더 큰 파라미터 수를 통제하기 위해 파라미터 매칭 트랜스포머(dim=768, 81.2M 파라미터)를 추가 학습한다.
데이터. 모든 모델은 GPT-2 BPE 토크나이저(어휘 크기 50,257)를 사용하여 OpenWebText 데이터셋으로 학습한다.
분석 도구. 200 스텝마다 체크포인트를 저장하고 다음을 추출한다: CMS 레벨 파라미터 노름 및 레벨 간 유사도, 자기수정 파라미터의 초기화 대비 드리프트, 토큰별 서프라이즈 값 분포, 메타 파라미터 대 빠른 상태 발산.
4. 결과
4.1 컴포넌트 제거 실험
| 변형 | 소규모 손실 | Δ | 대규모 손실 | Δ |
|---|---|---|---|---|
| Full HOPE | 7.216 | — | 7.237 | — |
| No CMS | 7.201 | -0.015 | 7.079 | -0.158 |
| No Self-Mod | 7.532 | +0.316 | 8.649 | +1.412 |
| No Surprise | 7.322 | +0.106 | — | — |
| Transformer | 6.880 | -0.336 | 7.830 | +0.593 |
| Transformer (매칭) | — | — | 7.936 | +0.700 |
| Titans | 7.578 | +0.362 | — | — |
Table 1: 컴포넌트 제거 실험 결과. Δ는 Full HOPE 대비 손실 차이 (양수 = 성능 저하). 각 규모에서 최고 결과를 굵게 표시.
세 가지 패턴이 나타난다.
CMS를 제거하면 일관되게 성능이 향상되었다: 소규모에서 -0.015, 대규모에서 -0.158. 다중 시간 스케일 계층은 학습에 기여하지 않으면서 파라미터와 연산만 추가한다.
자기수정을 제거하면 성능이 크게 저하되었다: 소규모에서 +0.316, 대규모에서 +1.412로 확대되어 중요도가 4.5배 커졌다.
소규모에서는 트랜스포머 기준선이 모든 HOPE 변형을 능가하지만(-0.336), 대규모에서는 HOPE가 역전한다(+0.593). 81.2M 파라미터의 파라미터 매칭 트랜스포머, 즉 HOPE의 73.1M을 초과하는 모델로도 격차를 줄이지 못했다(+0.700).
4.2 CMS 다중 시간 스케일 동역학
CMS는 빠른 학습 시스템과 느린 학습 시스템이 다른 유형의 정보를 포착한다는 보완적 학습 시스템 이론에 의해 동기 부여된다. 이러한 분리가 실제로 나타나는지 검증한다.
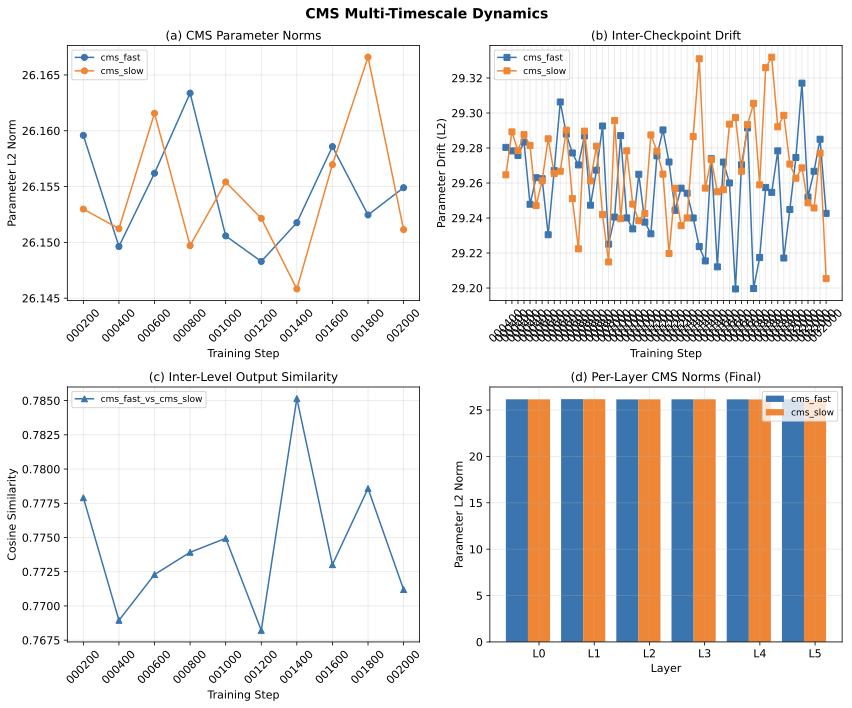
Figure 1: 학습 과정에서의 CMS 동역학. (a) fast와 slow 레벨 간 파라미터 노름이 거의 동일하게 유지됨. (b) 체크포인트 간 드리프트가 양 레벨에서 유사함. (c) fast와 slow 레벨 출력 간 코사인 유사도가 평균 0.77로 높은 중복도를 나타냄. (d) 레이어별 노름이 전 6개 레이어에서 균일한 행동을 보임.
파라미터 수렴. fast와 slow 레벨 파라미터의 L2 노름은 학습 전체에 걸쳐 서로 0.2% 이내로 유지되며 (양쪽 모두 ~26.15), 체크포인트 간 드리프트 크기도 거의 동일하다 (~29.2–29.3).
출력 중복성. fast와 slow 레벨 출력 간 코사인 유사도는 학습 전체에 걸쳐 평균 0.77이며, 분화 추세가 없다. 서로 다른 빈도로 업데이트됨에도 불구하고 (p_fast=8 vs. p_slow=32) 양 레벨이 유사한 표현으로 수렴한다.
균일한 레이어 행동. 레이어별 분석은 CMS 노름이 전 6개 레이어에서 동일함을 보여, 메모리 계층의 레이어별 특화가 없음을 시사한다.
이러한 발견은 CMS 제거가 성능을 향상시키는 이유를 설명한다: 두 레벨이 중복 연산을 수행하면서 최적화해야 할 파라미터만 추가하기 때문이다.
4.3 자기수정 수렴 분석
HOPE의 자기수정 메커니즘은 메타학습 네트워크로부터 "빠른 상태" 파라미터를 생성한다. 이 메커니즘이 의미 있는 적응을 만들어내는지 분석한다.
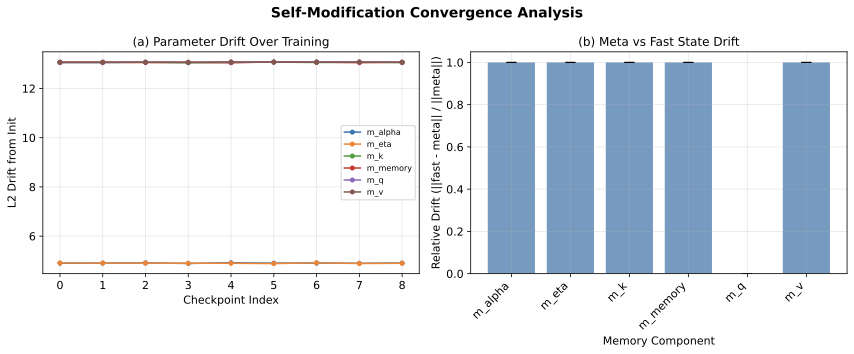
Figure 2: 자기수정 동역학. (a) 학습 과정에서 자기수정 파라미터의 초기화 대비 L2 드리프트. 큰 투영 행렬(m_k, m_v, m_memory)은 즉시 안정화되는 ≈13의 드리프트를 보이고, 작은 컴포넌트(m_η, m_α)는 ≈0.8–5의 드리프트를 보임. (b) 메타 파라미터와 빠른 상태 간 상대적 드리프트가 모든 컴포넌트에서 ≈1.0으로, 자기수정이 발생함을 확인.
초기화 대비 드리프트. 6개 레이어와 6개 메모리 컴포넌트 (m_k, m_v, m_q, m_η, m_α, m_memory)에 걸쳐 84개의 자기수정 파라미터를 추적한다. 큰 가중치 행렬은 Kaiming 초기화로부터 상당한 L2 드리프트(≈13)를 보이며, 작은 컴포넌트는 ≈0.8 드리프트를 보인다. 이 드리프트는 학습 첫 200 스텝 내에 발생하고 이후 거의 일정하게 유지된다. 자기수정이 지속적 온라인 적응이 아닌 학습된 초기화 오프셋으로 기능함을 시사한다.
메타 대 빠른 상태 발산. 추론 시점에 자기수정이 실제로 발생하는지 검증하기 위해 ‖θ_fast − θ_meta‖ / ‖θ_meta‖를 측정했다. 상대 드리프트는 모든 컴포넌트에서 ≈1.0이며, 빠른 상태 파라미터가 메타학습 생성기로부터 상당히 발산함을 확인했다.
해석. 자기수정은 실제로 발생한다. 빠른 상태 파라미터는 메타 파라미터와 의미 있게 다르다. 그러나 시간적 동역학을 보면, 메타 파라미터는 유용한 빠른 상태를 생성하는 구성을 빠르게 찾고, 이후 메타와 빠른 상태가 고정된 오프셋으로 함께 진화한다. HOPE 프레임워크가 제안하는 동적 자기수정보다는 "학습된 재파라미터화"에 가깝다.
4.4 서프라이즈 게이팅 효과
서프라이즈 게이팅은 모델이 예측하기 어려운 토큰에 메모리 업데이트를 집중시키도록 설계되었다. 이 선택적 메커니즘이 실제로 토큰을 구별하는지 평가한다.
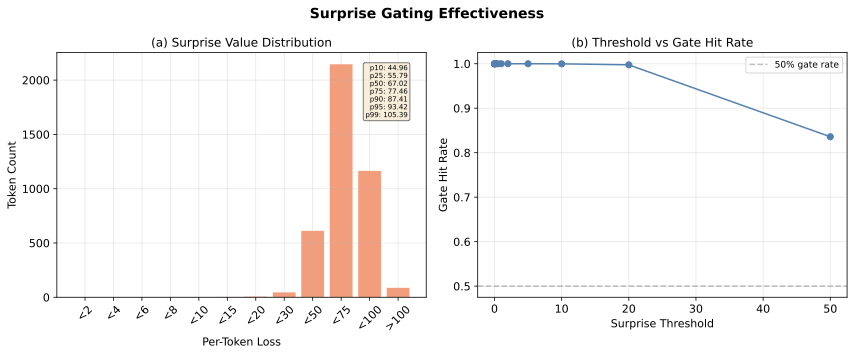
Figure 3: 서프라이즈 게이팅 분석. (a) 토큰별 손실값 분포 — 대부분 50과 100 사이에 집중 (중앙값 = 67.0). (b) 게이트 적중률 대 서프라이즈 임계값: 임계값=20에서도 99.8%의 토큰이 게이트를 통과.
손실 분포. 모델의 학습 규모에서 토큰별 교차 엔트로피 손실은 높은 범위에 집중된다: 평균 = 66.7, 표준편차 = 16.5, 최솟값도 9.3이다. 10번째 백분위수가 45.0으로, "가장 쉬운" 토큰의 손실도 합리적인 서프라이즈 임계값을 훨씬 초과한다.
게이트 선택성. 임계값 5.0까지 100%의 토큰에서, 임계값=10에서 99.97%, 임계값=20에서도 99.8%에서 게이트가 열린다. 임계값=50에서야 의미 있는 필터링이 시작되지만 (83.6% 통과율), 이 수준에서는 모델이 이미 부분적으로 학습한 가장 쉬운 토큰을 거부하는 것이다.
임계값 탐색.
| 임계값 | 0.005 | 0.01 | 0.02 | 0.05 | 0.1 |
|---|---|---|---|---|---|
| 최종 손실 | 7.289 | 7.243 | 7.222 | 7.222 | 7.304 |
| Δ (Full HOPE 대비) | +0.073 | +0.026 | +0.006 | +0.006 | +0.088 |
| 게이트 통과율 | 100% | 100% | 100% | 100% | 100% |
Table 2: 서프라이즈 임계값 민감도 (소규모). 모든 임계값이 >99.9%의 토큰을 통과시켜 무시할 만한 성능 차이를 보임.
서프라이즈 게이트는 실질적으로 무연산(no-op)이다. 이 메커니즘이 유효하려면 (a) 일부 토큰이 실제로 거의 0에 가까운 손실을 가지는 훨씬 크고 잘 학습된 모델이거나, (b) 절대적이 아닌 상대적 서프라이즈 지표가 필요하다. 현재 형태에서는 모든 토큰이 "놀라운" 것이다.
4.5 스케일링 효과
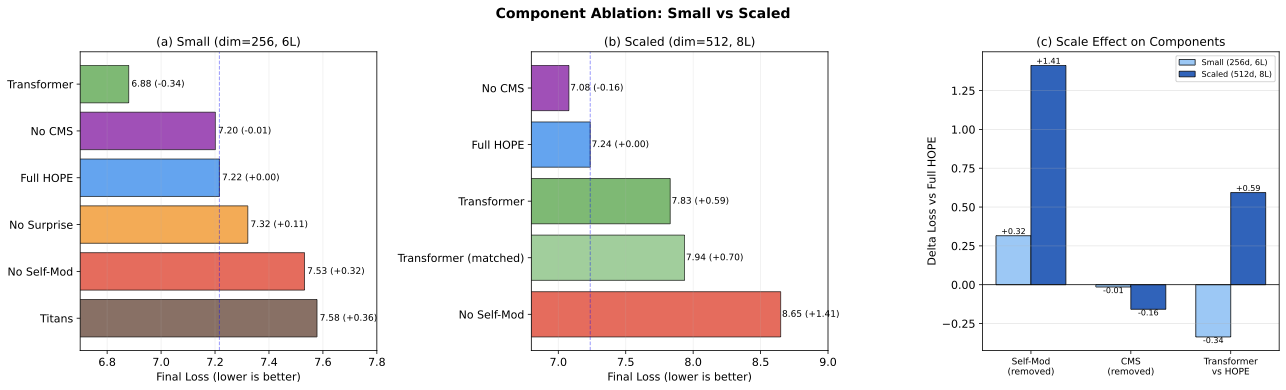
Figure 4: 규모별 컴포넌트 중요도. (a) 소규모 제거 실험 (dim=256, 6L). (b) 대규모 제거 실험 (dim=512, 8L). (c) 스케일 효과 비교: 자기수정 중요도가 4.5배 증가하고, 트랜스포머와 HOPE 간 스케일 역전이 -0.34에서 +0.59로 변화.
가장 두드러진 발견은 컴포넌트 중요도가 규모에 따라 어떻게 변하는가이다:
- 자기수정이 초선형으로 확장된다: 자기수정 제거 비용이 소규모에서 +0.32이지만 대규모에서 +1.41로 4.5배 커졌다. 모델 용량이 커질수록 적응적 재파라미터화의 혜택을 받는 파라미터가 더 많아지기 때문일 것이다.
- CMS는 양 규모에서 해롭다: CMS 포함의 페널티가 +0.015에서 +0.158으로 증가하여, 중복성 문제가 규모와 함께 악화된다는 뜻이다.
- 트랜스포머-HOPE 역전: 소규모에서 트랜스포머가 0.34 앞서지만, 대규모에서 HOPE가 0.59 앞선다. 역전의 원인은 자기수정이다. CMS 없이 자기수정만 남긴 "No CMS" 변형이 양 규모 모두에서 최고 성능을 달성했기 때문이다.
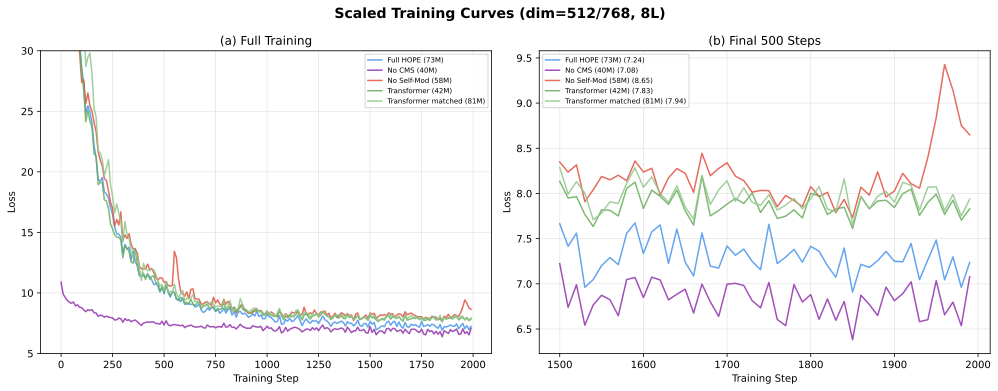
Figure 5: 대규모 학습 곡선 (dim=512, 8L). (a) 전체 학습 수렴 패턴. No Self-Mod 변형이 현저히 느리게 수렴하며 더 높은 손실에 도달. (b) 마지막 500 스텝에서 변형 간 명확한 분리를 보임.
파라미터 매칭 비교는 눈여겨볼 만하다. 81.2M 파라미터의 트랜스포머, 즉 HOPE의 73.1M을 초과하는 모델은 손실 7.936을 달성하여 HOPE의 7.237보다 나쁘다. 트랜스포머 용량을 늘려도 자기수정의 이점을 재현하지 못하며, HOPE의 장점이 파라미터 수가 아닌 메커니즘에서 비롯됨을 확인할 수 있다.
5. 논의
본질적 HOPE. 결과는 HOPE의 효과적 아키텍처가 제시된 것보다 상당히 단순함을 시사한다: CMS 계층이나 서프라이즈 게이팅 없는 자기수정 메모리 모듈. "No CMS" 변형 — 자기수정과 서프라이즈만 보유(서프라이즈는 무연산) — 이 테스트한 양 규모 모두에서 최고 성능을 달성한다.
CMS는 왜 실패하는가? 다중 시간 스케일 계층은 서로 다른 업데이트 빈도가 자연스럽게 특화를 유도할 것이라 가정한다. 분석 결과 이는 발생하지 않는다: 양 레벨이 4배 다른 업데이트 주기에도 불구하고 유사한 표현으로 수렴한다. 양 레벨을 통과하는 경사 신호가 너무 유사하고 (양쪽 모두 동일한 손실을 받음), 명시적 다양성 촉진 목적함수 없이는 시스템이 하나의 좋은 표현을 두 번 학습하는 것이 더 쉽기 때문으로 추정한다.
자기수정의 본질. 자기수정 메커니즘은 동적 온라인 적응보다는 "학습된 재파라미터화"로 더 잘 특성화된다. 메타 파라미터는 유용한 빠른 상태를 생성하는 생성기로 수렴하지만, 이 매핑은 학습 초기에 안정화된다. 이는 생성 네트워크가 대상 네트워크 가중치의 압축된 표현을 학습하는 하이퍼네트워크 행동과 유사하다. 성능 이점은 추론 중 동적 적응보다는 이것이 도입하는 암묵적 정규화와 파라미터 공유에서 비롯될 수 있다.
한계점. 실험은 73M 파라미터까지의 모델과 2,000 학습 스텝으로 단일 GPU에서 수행된다. CMS와 서프라이즈 게이팅에 대한 결론은 더 큰 규모에서는 유효하지 않을 수 있다 — (a) 토큰별 손실이 서프라이즈 게이팅 활성화에 충분히 낮을 수 있고, (b) 더 긴 학습이 CMS 레벨의 분화를 허용할 수 있다. 그러나 자기수정 스케일링 추세는 그 중요도가 규모와 함께 증가할 뿐임을 시사한다.
6. 결론
본 연구는 HOPE의 세 가지 메커니즘을 해부하였다. 자기수정이 HOPE 성능 우위의 유일한 기여자이며, 그 중요도는 모델 크기에 따라 초선형으로 확장된다(소규모에서 대규모로 4.5배). 다중 시간 스케일 CMS는 중복된 표현을 학습하여 테스트한 양 규모에서 성능을 해치며, 서프라이즈 게이팅은 학습 중 높은 토큰별 손실로 인해 작동하지 않는다. 자기수정의 성격은 지속적 온라인 적응이 아닌 학습된 초기화 이동으로 특성화된다.
이 결과를 실무에 적용하면, HOPE의 아키텍처는 성능 손실 없이 CMS와 서프라이즈 게이팅을 제거하여 단순화할 수 있다. 더 넓게는, 복잡한 신경망 아키텍처에서 메커니즘 간 상호작용이 이론적 예상과 크게 다를 수 있음을 보여준다.
Citation
@article{kim2025dissectinghope,
title={Dissecting HOPE: Do Self-Modifying Memories Actually Self-Modify?},
author={Kim, Junghun},
year={2025},
url={https://www.multi-turn.ai/blog/dissecting-hope}
}Abstract
HOPE (Higher-Order Parametric Experience) extends the Titans memory architecture with three novel mechanisms: multi-timescale contextual memory (CMS), self-modifying memory parameters, and surprise-gated updates. While the original paper demonstrates strong aggregate performance, the individual contribution of each mechanism remains unclear. We present a systematic dissection of HOPE through component ablations, internal dynamics analysis, and scaling experiments.
Our findings reveal a striking asymmetry: (1) self-modification is the sole driver of HOPE's advantage, with its importance scaling 4.5x from small to larger models; (2) the multi-timescale CMS provides no benefit at either scale, with fast and slow levels learning redundant representations (cosine similarity ≈ 0.77); (3) surprise gating is effectively inoperative, as per-token losses remain far above any reasonable threshold (mean = 66.7, min = 9.3), causing the gate to fire on >99.9% of tokens.
1. Introduction
Neural architectures with learnable memory systems have gained renewed interest as alternatives to the fixed key-value caches of standard Transformers. Titans introduced a memory module that stores and retrieves associative patterns through gradient-based updates, demonstrating competitive performance with subquadratic complexity. HOPE extends Titans with three mechanisms designed to improve memory utilization:
- Contextual Memory System (CMS): A multi-timescale hierarchy where fast, mid, and slow memory levels update at different frequencies, inspired by complementary learning systems theory.
- Self-modifying memory: Meta-learned parameters that generate the memory's key, value, query, and learning rate projections at inference time, enabling the model to adapt its own update rule.
- Surprise gating: A mechanism that gates memory updates based on per-token prediction loss, directing compute toward "surprising" inputs.
While HOPE reports improvements over Titans and Transformers, the original evaluation presents only aggregate metrics. This leaves open a critical question: which mechanisms actually contribute to performance, and do they function as theoretically motivated?
Our contributions:
- A complete component ablation at two scales showing that self-modification alone accounts for HOPE's advantage.
- Evidence that CMS fast/slow levels learn redundant representations and provide no measurable benefit.
- Analysis showing surprise gating is effectively non-selective at the loss magnitudes encountered during training.
- Characterization of self-modification dynamics as an initialization shift rather than continual adaptation.
- A scaling analysis revealing that self-modification's importance grows superlinearly with model size.
2. Background
Titans. The Titans architecture augments attention with a neural long-term memory module. Given an input sequence, the memory M is updated via gradient descent on an associative recall objective: M ← M − η∇ₘℒ(M; k, v). A surprise metric Sₜ = ‖ℒₜ‖ determines whether each token triggers a memory update.
HOPE. HOPE extends Titans along three axes. First, it introduces a CMS that maintains memory at multiple timescales: a fast level updates every p_fast tokens, a slow level every p_slow tokens, with outputs combined via learned gating. Second, it adds self-modification: rather than using fixed projection matrices, HOPE uses meta-learned networks m_k, m_v, m_q, m_η, m_α, m_memory that generate projections conditioned on a teaching signal. The generated parameters constitute a "fast state" that can diverge from the meta parameters during inference. Third, the surprise threshold is tuned as a hyperparameter controlling the selectivity of memory updates.
3. Experimental Setup
Model configurations. We evaluate two scales:
- Small: dim=256, 6 layers, ~19M parameters
- Scaled: dim=512, 8 layers, ~73M parameters
All models use a context length of 512 tokens and are trained for 2,000 steps with AdamW (lr=3e-4, batch size=8). CMS uses update periods of p_fast=8 and p_slow=32.
Ablation variants. We train the following at each scale:
- Full HOPE: All three mechanisms enabled (CMS + self-mod + surprise)
- No CMS: Self-modification and surprise without multi-timescale memory
- No Self-Mod: CMS and surprise without self-modifying parameters
- No Surprise: CMS and self-modification with surprise threshold=0
- Transformer: Standard Transformer baseline
- Titans: Original Titans architecture
At scaled, we additionally train a parameter-matched Transformer (dim=768, 81.2M parameters).
Data. All models trained on OpenWebText with a GPT-2 BPE tokenizer (vocab size 50,257).
Analysis tools. Checkpoints saved every 200 steps. We extract: CMS level parameter norms and inter-level similarity; self-modification parameter drift from initialization; per-token surprise value distributions; and meta-parameter vs. fast-state divergence.
4. Results
4.1 Component Ablation
| Variant | Small Loss | Δ | Scaled Loss | Δ |
|---|---|---|---|---|
| Full HOPE | 7.216 | — | 7.237 | — |
| No CMS | 7.201 | -0.015 | 7.079 | -0.158 |
| No Self-Mod | 7.532 | +0.316 | 8.649 | +1.412 |
| No Surprise | 7.322 | +0.106 | — | — |
| Transformer | 6.880 | -0.336 | 7.830 | +0.593 |
| Transformer (matched) | — | — | 7.936 | +0.700 |
| Titans | 7.578 | +0.362 | — | — |
Table 1: Component ablation results. Δ is the loss difference from Full HOPE (positive = worse). Best result per scale in bold.
Three patterns emerge.
First, removing CMS consistently improves performance: -0.015 at small scale and -0.158 at scaled. The multi-timescale hierarchy adds parameters and computation without contributing to learning.
Second, removing self-modification severely degrades performance: +0.316 at small scale, escalating to +1.412 at scaled — a 4.5x increase in importance.
Third, at small scale the Transformer baseline outperforms all HOPE variants (-0.336), but at scaled HOPE overtakes it (+0.593), and even a parameter-matched Transformer with 81.2M parameters (vs. HOPE's 73.1M) cannot close the gap (+0.700).
4.2 CMS Multi-Timescale Dynamics
The CMS is motivated by complementary learning systems theory, which posits that fast and slow learning systems capture different types of information. We test whether this separation emerges in practice.
Figure 1: CMS dynamics across training. (a) Parameter norms remain nearly identical between fast and slow levels. (b) Inter-checkpoint drift is similar for both levels. (c) Cosine similarity between fast and slow level outputs averages 0.77, indicating high redundancy. (d) Per-layer norms show uniform behavior across all 6 layers.
Parameter convergence. The L2 norms of fast and slow level parameters remain within 0.2% of each other throughout training (~26.15 for both), and their inter-checkpoint drift magnitudes are nearly identical (~29.2–29.3).
Output redundancy. The cosine similarity between fast and slow level outputs averages 0.77 across training, with no trend toward differentiation. Despite updating at different frequencies (p_fast=8 vs. p_slow=32), both levels converge to similar representations.
Uniform layer behavior. Per-layer analysis shows CMS norms are identical across all 6 layers, suggesting no layer-specific specialization.
These findings explain why removing CMS improves performance: the two levels perform redundant computation while adding parameters that must be optimized.
4.3 Self-Modification Convergence
HOPE's self-modification mechanism generates "fast state" parameters from meta-learned networks. We analyze whether this mechanism produces meaningful adaptation.
Figure 2: Self-modification dynamics. (a) L2 drift from initialization over training. Large projection matrices show drift ≈13 that plateaus immediately; small components drift ≈0.8–5. (b) Relative drift between meta parameters and fast state is ≈1.0, confirming self-modification occurs.
Drift from initialization. We track 84 self-modification parameters across 6 layers and 6 memory components. Large weight matrices show substantial L2 drift (≈13) from Kaiming initialization, while smaller components drift by ≈0.8. Critically, this drift occurs within the first 200 training steps and remains essentially flat thereafter. This suggests self-modification functions as a learned initialization offset rather than continual online adaptation.
Meta vs. fast state divergence. The relative drift ‖θ_fast − θ_meta‖ / ‖θ_meta‖ is ≈1.0 for all components, confirming that fast state parameters diverge substantially from their meta-learned generators.
Interpretation. Self-modification does occur — fast state parameters are meaningfully different from meta parameters. However, temporal dynamics reveal that meta parameters quickly find a configuration whose generated fast states are useful, and then both evolve together with a fixed offset. This is closer to a "learned reparameterization" than the dynamic self-modification suggested by the HOPE framework.
4.4 Surprise Gating Effectiveness
Surprise gating is designed to focus memory updates on tokens the model finds difficult to predict.
Figure 3: Surprise gating analysis. (a) Distribution of per-token loss values — bulk concentrated between 50 and 100 (median = 67.0). (b) Gate hit rate vs. surprise threshold: even at threshold=20, 99.8% of tokens pass the gate.
Loss distribution. Per-token cross-entropy losses are concentrated in a high range: mean = 66.7, std = 16.5, with minimum at 9.3. The 10th percentile is 45.0 — even the "easiest" tokens have losses far exceeding any reasonable surprise threshold.
Gate selectivity. The gate fires on 100% of tokens for thresholds up to 5.0, 99.97% at threshold=10, and still 99.8% at threshold=20. Only at threshold=50 does meaningful filtering begin (83.6% pass rate).
Threshold sweep.
| Threshold | 0.005 | 0.01 | 0.02 | 0.05 | 0.1 |
|---|---|---|---|---|---|
| Final Loss | 7.289 | 7.243 | 7.222 | 7.222 | 7.304 |
| Δ vs. Full HOPE | +0.073 | +0.026 | +0.006 | +0.006 | +0.088 |
| Gate pass rate | 100% | 100% | 100% | 100% | 100% |
Table 2: Surprise threshold sensitivity (small scale). All thresholds pass >99.9% of tokens.
The surprise gate is effectively a no-op. For this mechanism to be meaningful, it would require either (a) substantially larger models where some tokens genuinely have near-zero loss, or (b) a relative rather than absolute surprise metric. In its current form, every token is "surprising."
4.5 Scaling Effects
Figure 4: Component importance across scales. (a) Small-scale ablation. (b) Scaled ablation. (c) Scale effect comparison showing self-modification importance grows 4.5x, while the Transformer-HOPE reversal shifts from -0.34 to +0.59.
The most striking finding is how component importance changes with scale:
- Self-modification scales superlinearly: Removing self-mod costs +0.32 at small but +1.41 at scaled — a 4.5x increase. Larger models have more parameters that benefit from adaptive reparameterization.
- CMS remains harmful at both scales: The penalty grows from +0.015 to +0.158, suggesting the redundancy problem worsens with scale.
- Transformer-HOPE reversal: At small scale, the Transformer wins by 0.34; at scaled, HOPE wins by 0.59. This reversal is entirely attributable to self-modification — the "No CMS" variant achieves the best performance at both scales.
Figure 5: Scaled training curves (dim=512, 8L). (a) Full training convergence. No Self-Mod converges significantly slower to a higher loss. (b) Final 500 steps showing clear separation between variants.
The parameter-matched comparison is particularly informative. A Transformer with 81.2M parameters (exceeding HOPE's 73.1M) achieves loss 7.936 — worse than HOPE's 7.237. Increasing Transformer capacity does not replicate the benefit of self-modification, confirming that HOPE's advantage stems from the mechanism rather than parameter count.
5. Discussion
The essential HOPE. Our results suggest that HOPE's effective architecture is considerably simpler than presented: a self-modifying memory module without CMS hierarchy or surprise gating. The "No CMS" variant achieves the best performance at both scales tested.
Why does CMS fail? The multi-timescale hierarchy assumes that different update frequencies will naturally induce specialization. This does not occur: both levels converge to similar representations despite 4x different update periods. We hypothesize that the gradient signal through both levels is too similar, and without an explicit diversity-promoting objective, the system finds it easier to learn a single good representation twice.
Nature of self-modification. The mechanism is better characterized as a "learned reparameterization" than dynamic online adaptation. Meta parameters converge to generators that produce useful fast states, but this mapping stabilizes early in training. This is reminiscent of hypernetwork behavior. The performance benefit may stem from implicit regularization and parameter sharing rather than dynamic adaptation during inference.
Limitations. Our experiments use a single GPU with models up to 73M parameters and 2,000 training steps. Conclusions about CMS and surprise gating may not hold at larger scales where (a) per-token losses could be low enough for surprise gating to activate, and (b) longer training might allow CMS levels to differentiate. The self-modification scaling trend, however, suggests its importance only increases with scale.
6. Conclusion
We presented a systematic dissection of HOPE's three mechanisms. Self-modification is the sole effective contributor, with its importance scaling superlinearly with model size (4.5x from small to scaled). The multi-timescale CMS learns redundant representations and hurts performance at both scales, while surprise gating is rendered inoperative by high per-token losses. We further characterize self-modification as a learned initialization shift rather than continual online adaptation.
These findings have practical implications: HOPE's architecture can be simplified by removing CMS and surprise gating without loss of performance. More broadly, our work highlights the importance of component-level analysis for complex neural architectures, where the interaction between mechanisms may differ substantially from theoretical expectations.
Citation
@article{kim2025dissectinghope,
title={Dissecting HOPE: Do Self-Modifying Memories Actually Self-Modify?},
author={Kim, Junghun},
year={2025},
url={https://www.multi-turn.ai/blog/dissecting-hope}
}